Log Mangement ist ein komplexes und umfangreiches Thema. Das stellte ich mitunter auch fest, als ich zusammen mit Jan und Seppi von der Xware, einem Partner in Sursee, eine Präsentation vorbereitete. Log Management wird dann eben nicht nur als Logs sammeln, sondern auch das aggregieren, aufbereiten, analysieren und archivieren von Logs verstanden. In diesem Beitrag erläutere ich ein Beispiel-Anwendungsfall sowie gebe einen vertieften Einblick in den Leistungsumfang von Graylog.
Log Management
Kontext

Jan hat, um den Kontext von Graylog im gesamten Log Management zu verdeutlich, diese Grafik entwickelt. Sie zeigt, dass es eben nicht nur Logs, sondern daneben auch Metrics, Policies und Security als Bereiche des Log Management gibt und diese einzelnen Bereiche auch klar unterschiedliche Anforderungen haben. Graylog kann in allen diesen Bereichen mitwirken, ist jedoch eindeutig im Bereich Logging sehr stark und für Metrics, Policies und Security gibt es auch klar Produkte, welche dies dediziert anbieten.
Wieso eigentlich Logs sammeln?
Logs zu sammeln hat gute Gründe. NIST (NAtional Institute of Standards and Technology, USA) erläuter in „Guide to Computer Log Management 800-92“ gute Gründe: nebst den rechtlichen Vorgaben (wie HIPA, PCI DSS, SOX, …) gibt es auch einfach klar inhärente Vorteile. Nur dank Logs können Security Incidents, operationelle Probleme, Policy Violations und viel mehr überhaupt aufgefunden werden. Logs erlauben eine zeitnahe Analyse und ein gutes Tool dafür erlaubt eine zentrale und aggregierte Analyse der Logs.
Deep-Dive into Graylog
Wofür ist Graylog ideal?
Graylog ist ideal, wenn
- das Ziel ist, Logs zu sammeln, zu zentralisieren und auszuwerten.
- eine stabile, leistungsfähige und auch skalierbare Lösung gesucht wird, die auch gut mit Peaks umgehen kann.
- umfangreiche Funktionen zur Aufbereitung und Analyse von Logs notwendig sind.
Graylog ist ganz einfach ein leistungsfähiges und robustes Tool um Logs zu verarbeiten, zu analysieren und zu archivieren. Dabei besitzt Graylog eine tiefe Einstiegshürde (es ist schnell ein Ergebnis sichtbar) und dennoch eine umfangreiche Konfigurationsmöglichkeit.
Aus was besteht Graylog?
Graylog selbst besteht aus zwei Teilen: der Schnittstelle und der Weboberfläche. Die Schnittstelle ist in Java geschrieben und die Weboberfläche kommuniziert via HTTP(S) mit der Schnittstelle. Der Server selbst ist eine Komponente, das Empfangen und Verarbeiten der Logs geschieht in der selben Instanz. Graylog nutzt MongoDB als Meta-Speicher, sowie Elasticsearch als Speicher für die empfangenen Logs.
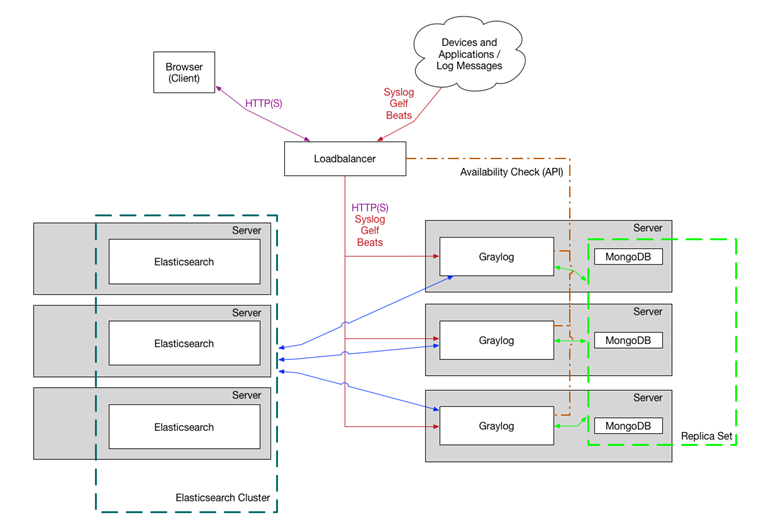
Graylog kann stark skaliert werden (mehrere Graylog Nodes, ein Cluster von Elasticsearch). Das ist jedoch kein „Muss“, sondern ein „Kann“. Mit einer 1:1:1 (1 Graylog, 1 MongoDB, 1 Elasticsearch) und etwas ausreichend CPU (Graylog) sowie Memory (Elasticsearch) kann auf wenig Hardware sehr viel erreicht werden. Erfahrungswerte sprechen hier von einem 4-Core 2.8 GHz und ca. 10 GB DDR3 RAM, welche für bis zu 500 Log-Einträge/Sekunde ausreichen. Dabei gilt hier klar: Logging auf Vorrat ist mit Bedacht zu führen. Nicht nur muss genügend Leistung auf dem Server vorhanden sein, auch die Netzwerktopologie muss genügend ausgelegt sein.
Inputs
Datenquellen werden in Graylog „Inputs“ genannt. Dabei wird eine Reihe von Quellen bereits als Standard mitgeliefert. Dabei sind die altbekannten NAmen mit dabei: Syslog, Microsoft Windows und CEF. Graylog selbst bietet das GEL-Format (Graylog Extended Log Format, GELF) an, ein JSON-basiertes Format, welches dynamisch um Felder erweitert werden kann. Möglich sind auch asynchrone Inputs über Message Queus wie Kafka oder RabbitMQ.
Sidecar
Es gibt jedoch auch den Use Case, wo keiner der vorhandenen Inputs anwendbar ist. Dafür gibt es den „Sidecar“, eine Applikation welche als Agent auf einem Host installiert wird und dort Logs sammelt und an Graylog weiterleitet.
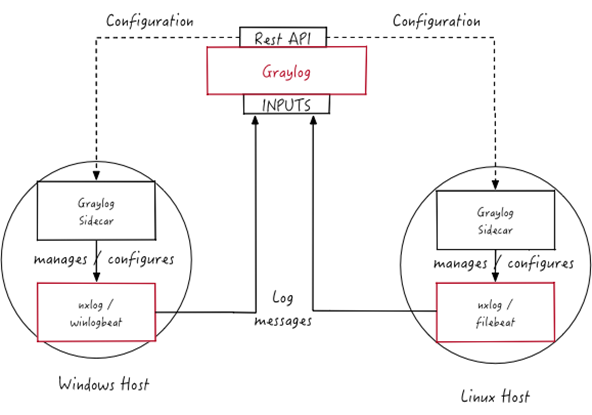
Dabei holt der Agent die Konfiguration von Graylog und sammelt entsprechend der, zentralisiert gespeicherten, Konfiguration, Logs. Übermittelt werden die Logs vom Sidecar zu Graylog via Beats-Protokoll, welches grundsätzlich nichts anderes als HTTP(S) ist. Sidecar unterstützt auch Certificate-based Client Authentication, sodass die Authentizität des Clients garantiert werden kann.
Retention und Archivierung
Logs werden standardmässig in Elasticsearch gespeichert. Dabei unterteilt Graylog die Logs automatisch ein einzelne Indices. Inputs können in eigene Indices gespeichert werden oder in den Standard-Index. Dabei können diese Indices auf Basis von Zeit, Grösse (Bytes) oder Anzahl Logs unterteilt werden. Die Speicherung ist relativ speicherperfomant, mit einer (Erfahrungswert) Grösse von cat 5 GB pro 3.5 bis 5 Millionen Einträge. Dabei gilt hier klar, dass der Memory für Elasticsearch als Kostenpunkt wohl einiges höher wiegt als die HD, auf der die Daten gespeichert sind.
Archivierung ist ein Enterprise-Feature, welches es ermöglicht, Logs langfristig zu speichern. Dabei werden alte Indices als komprimierte Dateien auf dem Dateisystem abgelegt und stehen nicht mehr Live zur Verfügung. Diese archivierten Indices können jederzeit wieder in Graylog importiert werden und stehen dann wieder Live in der Suche zur Verfügung. Der Zweck hiervon ist klar Compliance und Langzeitaufbewahrung.
Searching, Monitoring, Reporting
Graylog bietet umfangreiche Möglichkeiten zur Suche und Analyse von Logs. Die Suche funktioniert als Fuzzy-Search und Volltextsuche standardmässig über alle Felder. Dabei lassen sich Suchanfragen in der, an Lucene angelehnten, Suchsprache stellen. Einzelne Suchparameter lassen sich mit bool’sche Algebra verknüpfen.
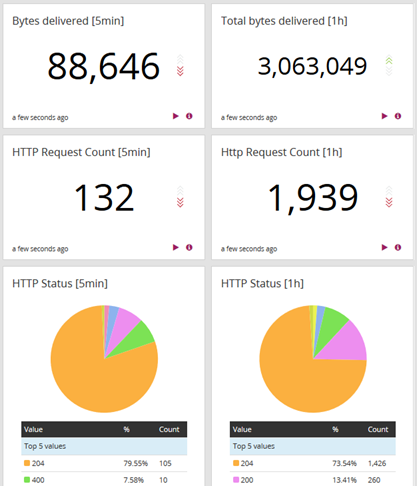
Die Suche bildet eines der Herzstücke von Graylog, denn sie ist in vielen anderen Bereichen wieder anzutreffen. So sind Views Suchanfragen, welche abgespeichert wurden und mittels einem Klick wiederhergestellt werden können (ähnlich einer View in einer Datenbank). Widgets, welche (siehe Screenshot oben) auf einem Dashboard positioniert werden, basieren auf Suchanfragen und können Suchergebnisse aggregieren. Das Reporting (Enterprise-Feature) basiert auch auf Suchanfragen, welche dann als PDF nach Zeitplan per E-Mail versendet wird. Auch Alerts, welche die Benachrichtung via Slack oder auch Microsoft Teams ermöglichen, basieren auf Suchanfragen: überschreitet ein Suchergebniss einen Schwellenwert, wird ein Alert ausgelöst.
Die Möglichkeiten, die Graylog hier bietet, sind sehr umfrangreich. Und das ist, meiner Meinung nach, auch einer der USP von Graylog: Es macht etwas, und dafür dieses etwas richtig gut.
Graylog und die Konkurrenz
Im Vergleich zur Konkurrenz steht Graylog gut da. Splunk ist in einigen Bereichen Graylog überlegen, wobei sich Graylog hier stärker auf Logs fokussiert und weniger drumherum bietet. Graylog bietet eine geringe Einstiegshürde und setzt dabei jedoch mehr Vorüberlegung voraus, wo Splunk mehr einen ad-hoc Ansatz verfolgt.
ELK (Elasticsearch, Logstash, Kibana) ist zwar sehr leistungsfähig, ist dabei auch eher low-level angesiedelt und kann ohne Entwickler wohl kaum in Betrieb genommen werden.
Preislich ist Graylog einerseits als Open Source-Variante unbegrenzt kostenlos verwendbar. Die Enterprise-Ausführung ist bis 5 GB/Tag kostenlos, danach besteht ein volumenbasierter Preis. Graylog schneidet in diesem Bereich insbesondere gut ab, weil die Steigung der Preiskurve eher gering ausfällt.
Schlusswort
Wir können Graylog auf jeden Fall nur empfehlen. Graylog ist bei uns bereits in mehreren Projekten im Einsatz. Die erste Inbetriebnahme ist auch mit überschaubarem Aufwand möglich, was Graylog sehr interessant macht, wobei es ohne Schwierigkeiten möglich ist, nachträglich zu skalieren.
Im Vergleich mit der Konkurrenz besticht Graylog durch ein gutes Preis-Leistungsverhältnis und den Fokus auf das Wesentliche. Gerade für Log Management ist es das ideale Tool und für Use Cases mit Workaround-Charakter gibt es besser geeignete Tools.
Gerne stehen wir Ihnen für eine Demonstration, eine Use Case-Analyse oder auch in einem allgmeinen, unverbindlichen Gespräch sehr gerne zur Verfügung. Nutzen Sie dafür den Live-Chat oder unsere Kontaktangaben.
Ein Dank hierbei nochmals an Josef Muri und Jan Jambor von der Xware, welche mich tatkräftig fachlich unterstützt haben.
Beitragsbild by Mitchel Boot on Unsplash